Database optimization for high-performance Java applications.
-
Share:
-

-

-

Database indexes: A double-edged sword
Indexes are one of the most powerful tools for improving database query performance. However, this speed boost comes at a cost. When you update, insert or delete data, the indexes must also be updated, which adds overhead.
The key is to find the right balance. Add indexes to optimize your most common and performance-critical queries. But be cautious about over-indexing, which can significantly degrade write performance. Monitor your workload and adjust the index strategy accordingly.
The alternative solution is to create a materialized view or use the CQRS pattern — which will also be discussed in this article.
N+1 problem
The N+1 problem is a common performance pitfall that occurs when an application executes more queries than necessary to retrieve the data.
For example, if you fetch a list of users and then make a separate query to fetch the address for each user, you end up with N+1 queries (1 to fetch the users, and N to fetch the addresses).
<b>List<User> users = userRepository.findAll();
for (User user: users) {
List<Address> addresses = addressRepository.findByUser(user);
<i>// Do something with the user and their addresses
</i>}</b>
Assuming we have 1,000 users in the database, and each user has 3 associated addresses, using the N+1 approach, the total number of database queries executed would be:
- 1 query to fetch the 1,000 users
- 1,000 queries to fetch the addresses for each user (1 query per user)
This means a total of 1,001 database queries are executed to retrieve the users and their addresses.
In contrast, if we could fetch the users and their addresses in a single, optimized query, the total number of queries would be just 1. This would significantly reduce the overall execution time and improve the application's performance.
The N+1 problem is a common pitfall when working with ORMs (Object-Relational Mapping) frameworks, such as Hibernate or Spring Data JPA. These frameworks provide abstractions that make it easy to work with databases, but they can also hide the complexity of the underlying queries, leading to unexpected performance issues.
There are a few common approaches to resolving the N+1 problem in Java applications. The most common is Join Fetching.
You can use the JPQL (Java Persistence Query Language) or Criteria API to fetch users along with their addresses in a single query using a JOIN FETCH. This approach reduces the number of queries to just one.
List<User> users = entityManager.createQuery(
"SELECT u FROM User u JOIN FETCH u.addresses", User.class)
.getResultList();
Otherwise, you can do the same by defining custom repository methods and using the @Query annotation to specify your JPQL query with the join fetch:
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u JOIN FETCH u.addresses")
List<User> findAllUsersWithAddresses();
}
Finding out when there is an N+1 query problem can be tough. This problem isn't easily caught by common testing methods. Whether you're testing small parts (unit tests), specific functions (functional tests) or whole systems (integration tests), they won't usually show whether the data loads slowly or quickly. While performance tests might point out a problem, having just one N+1 query issue usually doesn't cause a major slowdown. One possible approach is to turn on SQL logging:
spring.jpa.show-sql=true
To beautify or pretty-print the SQL, we can add:
spring.jpa.properties.hibernate.format_sql=true
This approach helps to verify what SQL requests are generated when you are testing your ORM code. We recommend always using this feature because ORM-generated code is not a thing that you can trust recklessly.
However, detecting the N+1 problem is still difficult when refactoring a big application. One way to do it is to collect the statistics of all SQL requests generated in the application. If you notice that some requests are executed more often than others, this is a candidate for the N+1 problem. To collect the statistics, we can use one of many APM tools — this will be discussed later.
Ways to optimize the bottlenecks
The first 2 techniques are recommended for every case of relation database usage and can be applied even for not-so-highly loaded applications.
The following tips should be applied with caution and only when you experience performance issues.
Use embedded databases
Embedded databases, which run within the same Java Virtual Machine as your application, can provide a major performance boost compared to remote database connections. With no network overhead, embedded databases can operate at near in-memory speeds.
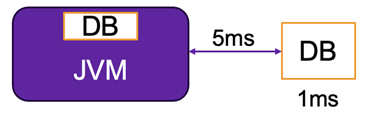
The tradeoff is that embedded databases are generally smaller in scale and have less advanced features than enterprise-grade databases. Also, it’s impossible to connect to the embedded database from outside. However, it can be used as temporary storage. The embedded database can be up to 100 times faster than the remote, especially for simple queries.
Optimize SQL requests
While our focus has been on higher-level strategies, traditional SQL optimization is still important. Techniques like execution plan analysis, indexing and query rewriting can yield significant performance gains. When queries become overly complex, it's often better to decompose them into simpler, more optimized pieces.
Use stored procedures
Stored procedures, which encapsulate database logic on the server side, can dramatically improve performance compared to client-side SQL execution. By reducing network round trips and allowing the database to handle complex operations internally, stored procedures minimize communication overhead.
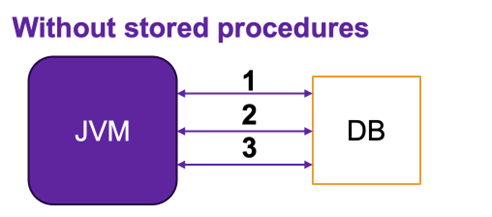
Assume communication overhead is 200ms, and a single operation takes 50ms.
If logic is implemented on the side of the application, every command will require a separate communication round trip.
1. Retrieve data (query time: 5ms, communication: 200ms)
2. Update table 1 (SQL request time: 50ms, communication: 200ms)
3. Update table 2 (SQL request time: 50ms, communication: 200ms)
Total time: 705 ms
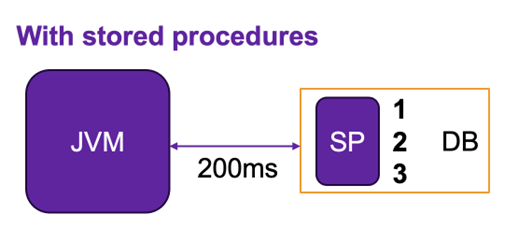
In cases where we do the same in a stored procedure, we need only a single communication — it takes 200ms.
Also, we need time to:
- Retrieve data — 5 ms
- Update table 1 — 50 ms
- Update table 2 — 50 ms
The total time in this case is 305 ms.
The tradeoff is that stored procedures can make your application more tightly coupled to a specific database engine. Also, the logic is distributed between the application and the database, which makes it more difficult to handle. But in performance-critical scenarios, the benefits often outweigh the drawbacks.
End of the Part #1

Sonkin Vladimir
![]()


